Your Company Doesn't Ask a Million Questions. It Asks a Countable One.
On June 3rd, Anthropic published one of the clearest explanations of why naive natural-language-to-SQL fails that anyone has written this year — and then, almost as an aside, told you the price of fixing it. Their analytics agents hit ~95% accuracy. Out of the box, before the scaffolding, that same setup scored 21%. The 74 points in between aren't a model upgrade — they're a permanent engineering organization. It's a genuinely great piece. It's also a blueprint maybe 5% of companies can build and even fewer can keep alive. This is the argument for the other road: the one where you don't generate SQL from scratch and hope it's right, you take a query that's already been tested and let AI reshape it at runtime. Deterministic by default. Accurate because it was validated once, not hopefully, every single time.
The 21% That Anthropic Was Honest About
On June 3rd, Anthropic published a blog post titled How Anthropic enables self-service data analytics with Claude. Read it. Then read it a second time as something its authors may not have fully intended it to be: the most rigorous public case against naive natural-language-to-SQL written all year.
The piece is excellent, and it's honest in ways most vendor content never is. It says plainly that pointing an AI agent at a warehouse and letting it execute can create a false sense of precision — that the initial elation of escaping ad-hoc requests turns into dread once you realize the agent has quietly separated your stakeholders from the documentation and expertise that used to keep them on the rails.
And buried in that honesty is a single number every executive weighing a just point an AI at our data pitch should sit with quietly for a minute. Out of the box, before any of the surrounding machinery, Anthropic's own analytics setup answered questions correctly 21% of the time.
The celebrated 95% figure is real. But it is not a property of the model. It is a property of everything Anthropic built around the model. The 74 points between 21% and 95% are not an upgrade you download. They're an engineering organization you staff, fund, and never stop feeding.
We don't think Anthropic is wrong. We think they're right — and that being right makes the case for a different road for the 95% of companies that are not Anthropic.
There Are Two Kinds of Questions, and NL2SQL Only Safely Answers One
Start with a distinction the hype tends to flatten: not every business question needs to be correct. Plenty just need to be good enough. An analyst poking around to form a hypothesis, a PM sizing a rough opportunity, a marketer eyeballing a directional trend — for them, an answer that's approximately right and arrives in ten seconds is a genuine win. This is where out-of-the-box NL2SQL legitimately shines, and we'd never argue otherwise.
Then there's the other kind. The number a CFO puts on a board slide. The retention figure that anchors a fundraise. The metric a regulated enterprise has to defend to an auditor. These don't just need to be accurate — they need to be deterministic. Ask the same question on Tuesday and Thursday and you must get the same answer, derived the same way, every time.
Here is the structural problem, and Anthropic names it themselves: generative models are generative. The same mechanism that lets them write creative SQL also lets them hallucinate, and for an analytics question there is often exactly one correct answer from one correct source — with no deterministic way to prove the agent found it. The same prompt can compile to different SQL, and therefore a different number, on different runs. That is not a bug you patch. It is what generation is.
Compounding it is an inversion most teams don't see until it's bitten them. In the old world, curated datasets and tribal knowledge steered users toward the right answer. In the new world, the end user is no longer a data expert — which means they can't validate the result, because they don't know enough to know it's wrong. So when the agent confidently returns a plausible, wrong number, who catches it? Anthropic is candid that this silent-failure mode is the one their entire stack still doesn't fully solve. They don't have a robust answer yet. Neither does anyone shipping raw NL2SQL into a non-technical audience.
The Receipts
What 95% Actually Costs
Anthropic is admirably specific about what it took to climb from 21% to 95%. It's worth listing, because the list is the argument:
A small set of aggressively governed canonical datasets, with near-duplicates deliberately deprecated. A human-owned semantic layer — they tried having an LLM auto-generate the metric definitions and found it net-negative, because the machine cheerfully encoded the very ambiguities they were trying to kill. CI gates that fail any change bypassing the governed layer. Skill documentation colocated in the same repo as the models, such that ~90% of their data-model pull requests now touch a skill file in the same diff. Offline and online evaluation harnesses. Adversarial review sub-agents that improved accuracy by ~6% — at the cost of 32% more tokens and 72% higher latency. And a fleet of correction-harvesting bots that scan Slack for someone saying that's the wrong table and open a fix PR.
This is not a project with an end date. It's a standing tax. The clearest proof is their own admission that offline accuracy drifted from ~95% to ~65% over a single month when maintenance lapsed. The data model changes daily, so the scaffolding describing it goes stale within weeks. Stop feeding the machine and it quietly degrades back toward that 21%.
Now ask the honest question for your own company: do you have a data engineering team that can build dimensional models, own a semantic layer, wire eval suites into CI, run adversarial sub-agents, and dedicate humans to perpetual documentation upkeep — forever? For a handful of frontier-scale companies, the answer is yes, and they should absolutely follow Anthropic's playbook to the letter. For the overwhelming majority, this isn't a matter of won't. It's can't. The Nirvana state is real. It's just not reachable from where most businesses actually stand.
The Reframe: Your Demand Is Countable
Here's the assumption baked into the whole NL2SQL premise, and it deserves to be challenged directly: that the job is to map any question to any of millions of fields. That's true at the frontier of analysis. It is emphatically not true for what your business asks on a normal Tuesday.
Companies don't generate a million distinct questions. They ask a finite, knowable set — repeated constantly, then sliced, pivoted, filtered, and re-windowed. What's revenue by region this quarter. What's it by region last quarter. Now by segment. Now month-over-month. Same underlying question, a dozen cuts. The variation is real, but it lives at the edges of a small, stable core.
You can prove this to yourself. Put a semantic layer over your entire dashboard and analytics estate and ask one question of it: what did all of these actually compute? The sprawl collapses. In one engagement with a large U.S. health enterprise, the analytics estate had grown past 20,000 Tableau dashboards. When we mapped what those dashboards genuinely measured — not how many there were, but what business questions they answered — the same handful of metrics appeared again and again and again. Twenty thousand artifacts. A countable number of real questions underneath.
The Pareto Shape of Business Questions
The repeatable 80%. Answered by a small, knowable set of validated analytics, conditioned at runtime.
The genuine long tail. Novel, one-off questions where exploratory NL2SQL legitimately earns its keep.
Roughly 20% of your analytics answers about 80% of the questions your business actually asks.
Once the real demand is countable, it's tractable. You don't have to solve open-ended question-answering across infinity. You have to encode the countable set of questions your business genuinely asks — and let AI handle the slicing and pivoting on top of answers that are already known to be correct.
Validate Once. Condition Forever.
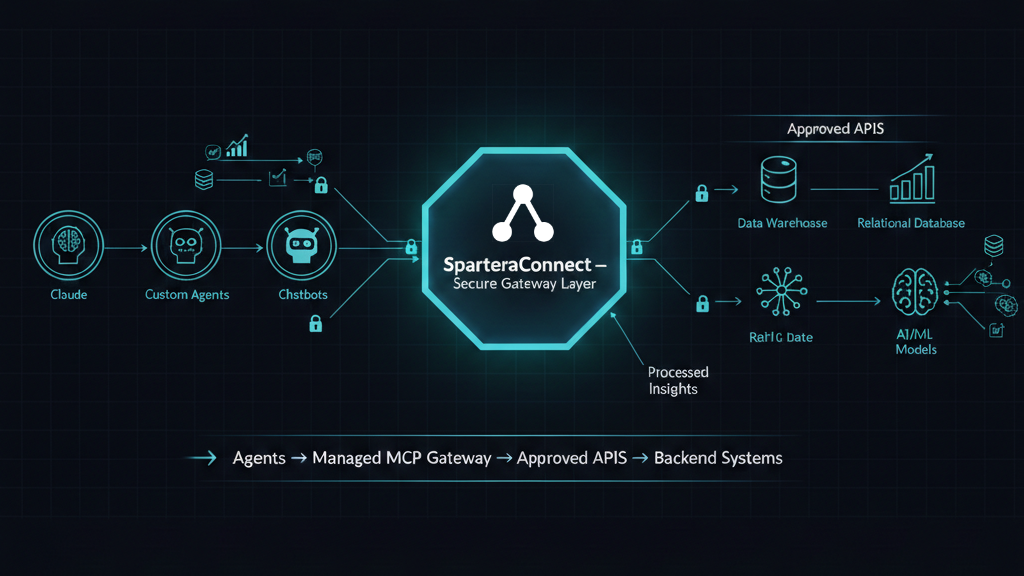
This is the architecture Spartera is built on, and it's a deliberate inversion of the NL2SQL bet.
Instead of generating SQL from scratch on every request and hoping it's right, you start from a query that has already been written, tested, and validated against the real schema by someone who knows what the answer should be. The expensive, error-prone act of generation happens once. From then on, AI's job is narrow and safe: condition that validated query at runtime — swap the date window, change the segment filter, pivot the dimension, adjust a parameter. That's a tiny, bounded surface compared to authoring arbitrary SQL across a million-field warehouse.
The result is a deterministic core with flexible edges. Ask the same question twice and you get the same query, and therefore the same number — every time, defensibly, with the verification burden paid once by the author rather than repeatedly by a user who couldn't catch a wrong answer if it bit them.
And if you want the single most compelling endorsement of this approach, it's in Anthropic's own article. They ran the experiment: they gave their agent direct grep access to thousands of validated prior queries from dashboards and notebooks, confirmed it actually read them, and measured the lift. Accuracy moved by less than a point. The information was right there, the agent saw it, and it still didn't reliably use it. Their conclusion — the bottleneck was never access to prior work, it was structure: mapping a question to the right entity — is the entire Spartera thesis, stated in Anthropic's voice. A curated, structured set of validated queries beats raw generative firepower turned loose on a warehouse.
Diminishing Returns on the Road to 95%
The first ~80% comes fast and cheap. Every point after that costs disproportionately more — and never stops costing.
Three Roads, Honestly Compared
None of this means NL2SQL is bad. It means it belongs somewhere specific. Here's the honest landscape:
| Approach | Accuracy | Deterministic? | Setup & Upkeep | Who Verifies | Best Fit |
|---|---|---|---|---|---|
| NL2SQL out-of-the-box | ~21% baseline | No | Minimal to start | The reader (who often can't) | Exploration, “good enough” answers |
| Full agentic stack | ~95% | No (probabilistic) | Very high + permanent | Built-in, human-owned layers | Large data orgs, technical consumers |
| Spartera validated queries | High & repeatable | Yes — tested once | Some, then low | The author, once | Leadership, regulated, repeatable questions |
We'll be straight about the one place validated queries genuinely can't reach: the truly novel, never-before-asked question that sits outside the library. For those, you have two honest options. Fall back to exploratory NL2SQL and treat the answer as directional. Or — and this is where it compounds — author the query once, validate it, and add it to the library, at which point that question is deterministic forever after. Every new question makes the system stronger instead of riskier. And as models improve, that authoring step is increasingly something AI drafts and a human confirms, rather than writes from scratch. The library is an asset that appreciates. A fresh generation on every request is a risk you re-run every time.
You Don't Have to Choose Between Nothing and Everything
The false binary in most self-service analytics conversations is do nothing versus build Anthropic's data organization. That framing leaves the 95% of companies who can't staff a permanent agentic stack stuck — either tolerating wrong answers from raw NL2SQL, or tolerating the same dashboard sprawl they've always had.
There's a middle road, and it's the pragmatic one. Yes, Spartera requires some setup — we won't pretend otherwise. But because most of your real demand collapses into a countable set of questions, a modest investment in validated, runtime-conditioned queries gets a business roughly 80% of the way to genuine self-service, with deterministic answers leadership can actually defend, on a fraction of the effort and with none of the permanent maintenance tax. The expensive last 15 points to a theoretical 95%+ — the part that demands a standing engineering org — simply isn't where most companies need to spend to unlock most of the value.
Anthropic wrote the definitive guide to how hard the hard road is. We read it as confirmation. Get the repeatable 80% right first, deterministically, with minimal setup. Reach for generative firepower at the genuine long tail, where being approximately right is good enough. That's not a compromise. That's the architecture that actually ships.
Surface Your Insights
See how validated, runtime-conditioned analytics get your business to self-service with minimal setup.
Get Started TodayBrowse the Marketplace
See what 18,000+ validated analytics products look like in production.
Explore ProductsFind Your Countable Set
A Demand Intelligence Analysis maps the real questions hiding under your dashboard sprawl.
Learn About DIAYour company doesn't ask a million questions. It asks a countable one. The fastest path to answering them well isn't teaching a machine to guess — it's validating the answers once, and letting AI do the rest.